A Study on Cloud Computing Architecture in Big Data
Number of words: 13664
Table of Contents
| Introduction | 3 |
| Purpose of the research | 4 |
| Background and Methodology | 4 |
| Aim of the research | 5 |
| Literature review | 6 |
| Research Methodology | 20 |
| Systems of Big Data Analytics in the Cloud | 24 |
| 1) Map Reduce | 24 |
| 2) Spark | 24 |
| 3) Mahout | 24 |
| 4) Hunk | 24 |
| 5) Sector and Sphere | 25 |
| 6) BigML | 25 |
| 7) Data Analysis workflows | 26 |
| Analysis | 29 |
| FUTURE SCOPE | 32 |
| The Upcoming Relevance of Cloud Computing: | 32 |
| Top 3 areas whereby cloud hosting may be used that will thrive in the future: | 32 |
| Data Backup | 32 |
| Education | 32 |
| Entertainment | 33 |
| CONCLUSION | 34 |
| Commonalities between big data and cloud computing: | 34 |
| References | 37 |
Introduction
This research deals in studying the architecture of cloud computing in the field of big data in which we collected a tremendous quantity of data from people, actions, sensors, analytics, and the browser in this data-driven world; managing “Big Data” has now become a big issue. There is still some debate over when data may be referred to be big data. What is the size of big data? What’s the link among big analysis and business intelligence? What is the best method for saving, modifying, retrieving, analysing, managing, and recovering large amounts of data? How might cloud computing assist in dealing with large data issues? What function does a cloud architecture play in large data management? What role does big data play in business intelligence? This chapter makes an attempt to provide answers to all the questions (Zhang et. al. 2017). First, we’ll look at a definition of large datasets. Second, we discuss the significant problems of storing, analysing, preserving, recovering, and retrieving large amounts of data. Third, we explain the impact of Cloud Computing Infrastructure as a solution to these critical big data challenges. We also go through the definition and key characteristics of cloud computing platforms. Then we’ll go through how public cloud may help with big data by providing cloud services and open-source cloud software solutions. Finally, we discuss the function of cloud infrastructure in big data, the key cloud service tiers in big data, and also the function of cloud computing environment in massive data handling
Purpose of the research
When contemplating the usage of Big Data analytic methodologies, data storage via cloud computing is a realistic alternative for small to medium-sized organisations. Cloud computing is an on network connectivity to computer resources that are frequently offered by a third party and requires little administrative effort on the part of the company. There are several cloud technology architectures and deployment models available, and these structures and models can be combined with certain other technologies and advanced methods. Owners of small to medium-sized enterprises that cannot afford clustered NAS equipment can investigate a variety of cloud computing solutions to suit their big data demands. The assessment of big data is being pushed by fast growing cloud-based applications built using virtualized technology. It has been discovered that the cloud services infrastructure may be used for the execution of duties as an effective option to tackle the issue of file storage necessary to execute advanced data analytics. The link of cloud computing exists with a new pattern of computational equipment deployment and the big data processing method. As big data processing has gotten more complicated, it is critical for many cloud-based solutions to manage the new environment (Manogaran et al. 2017).
Background and Methodology
Businesses undoubtedly generate enormous amounts of data as a result of corporate operations, sensor surveillance of user behaviour, website advertising, finance, bookkeeping, and other factors. End users build their own accounts on social networking websites to broadcast their appearance and accomplishment in many locations via message or image. The merging of these enormous groups of data is known as Big Data. A phrase that describes the problems it brings to current facilities in terms of data storage, administration, interoperability, accountability, and analysis. In today’s competitive market, being able to gather data to analyse consumer activity, separate customer base, and offer customised services is essential. These policymakers would prefer to base their judgments and operations on data insights, which makes sense.
Collecting data, obtaining quasi patterns from data, and employing these patterns to forecast the future events tendency is the main key of this study. The goal of Knowledge Discovery in Data (KDD) would be to extract data that is not readily apparent. This research paper presents an analysis that is detailed and clear in terms of data gathering and analysing. Data models are built using data from many sources such as data bases, data streams, data marts, and information repositories. Because of the huge number of diverse types of data, or before procedures such as data cleansing, integration, and data may be required. Clean data for training a machine and estimate its parameters with constraints. When one model is predicted, it really should be verified before it is used. In general, this step necessitates the usage of the actual input information as well as unique procedures to validate the newly constructed model. Finally, the model is compiled and applied to new data as it comes in (Psannis et al. 2018).
The research is descriptive in nature and because descriptive analytics examines previous data to detect trends and provide management reports; it is interested with forecasting future behaviour. Predictive analytics is a technique for forecasting the future by evaluating current and past (historical) information. Prescriptive Solutions assists analysts in making judgments by determining activities and evaluating their impact in relation to corporate objectives, needs, and limitations. Current analytical methods are frequently based on proprietary hardware or broad sense software platforms. Technical concerns are addressed, and previous works on technologies to offer analytical strength for Big Data on the Cloud Computing Environment is surveyed. Taking into account the typical analytics workflow, during the phases of an analytics solution, we focus on critical concerns. Many of the problems of Cloud Analytics are obvious with Big Data, including data management, connection, and processing. Previous research has concentrated on file types, access, data representation, preservation, privacy, and data integrity.
So this is the background of the study and we can clear understand about the further and future study which is going to be happen.
Aim of the research
The main of the research is to find out how the cloud computing concept can conjugate well in the big data as these two are the whole different concept. In this study we will also find out how other concept like internet of things, artificial intelligence can contribute in between big data and cloud computing.
Lastly we will also study the relationship and the advantages of using the cloud computing by using big data. A sample of large population has taken and ideas have took from the previous researches to make this study more compatible and genuine.
Literature review
According to Barik et al. 2018: Cloud computing can benefit from offloading part of the processing and tactical decision to the border, either near to the patient’s experience or the cloud backbone. The term “Fog of Things” consists of a collection of fog nodes that may interact with one another over the Internet of Things. Heavily loaded processing, long-term preservation, and analysis are all completed on the cloud. We offer flexible and user-oriented implementation frameworks GeoFog and Fog2Fog. In these kind of systems, fog devices function as intermediary intelligent nodes, deciding whether or not additional processing is necessary. Preliminary data processing, signal filtration, data cleansing, and extraction of features may all be performed on edge computers, reducing computing burden in the internet. In some practical instances, such as telehealth for Parkinson’s disease sufferers, information technology may opt not to proceed with data transfer to the cloud. We discuss the notion of integrating machine learning including such clustering, deciphering deep computational methods, and so on on fog devices at the conclusion of this scientific report, which might lead to scalability inferences. The topic of fog-to-fog communication is explored in relation to modelling techniques for electricity savings. Future research objectives, difficulties, and management methods are also explored. We describe case studies in which proposed architectures were used in a variety of application domains. The usage of edge devices for computation offloads processing from the cloud, resulting in increased power and effectiveness. Four cloud technology trends are broadening the scope of cloud products and capabilities, driving growth across all areas of the public cloud services industry. Future research aims, challenges, and management techniques are also discussed. We present case studies in which proposed designs were employed in a wide range of application fields. The use of computer network edge offloads computing from the internet, resulting in greater power and performance.
According to Stergiou et al. 2018: We are gathering tremendous quantities of information from individuals, activities, sensors, analytics, as well as the internet in this data-driven world; managing “Big Data” has now become a big issue. There is still some debate over when information may be referred to be big data. What is the size of big data? What’s the link among big data and business intelligence? What is the best method for saving, modifying, retrieving, analysing, managing, and recovering large amounts of data? How might cloud technology assist in dealing with large data issues? Cloud infrastructure is easy and adaptable, and data may be accessed, archived, and maintained. A VPN or a basic internet connection allows you to access sky systems and resources like Netflix, Skype, or Google Docs. Because of the advantages of massive memory and speed, businesses adopt cloud computing architecture. Users from all around the universe can view the data in the cloud. What function does a cloud infrastructure play in large data management? What role does big data play in business analytics? First, we’ll look at a description of big data. Second, we discuss the significant problems of storing, analysing, preserving, recuperating, and retrieving large amounts of data. Third, we discuss the role of Cloud Computing Environment as a solution to these critical big data challenges. We also go through the definition and key characteristics of cloud services. Then we’ll go through how public cloud may help with big data by providing cloud services and cloud infrastructure software solutions. Finally, we discuss the importance of cloud environment in big data, as well as the importance of key cloud service tiers in big data. All of the necessary customization and installation steps for running a cloud platform are handled by deployment programs. Every cloud service must pass via installation software. The elements of deployment software include Software and services, Platform as a Service, and Cloud infrastructure.
According to Elhoseny et al. 2018: Cloud computing is critical in analysing massive amounts of data. However, with the invention of the Internet of Things, these gadgets create massive amounts of data. As a result, there’s any need to introduce cloud features closer to the demand generator, so that analysis of these massive data sets may actually occur at a one-hop length closer towards the end user. This resulted in the creation of cloud environment, which aims continue providing storage and processing at the network’s edge, reducing network activity and overcoming many of the disadvantages of cloud computing. Cloud computer science aids in the resolution of massive data processing issues. Big Data systems are frequently made up of parts for extracting information, pre-treatment, computing, ingest and incorporation, analysis of data, communication, and visualisation. Varied big data systems will also have diverse demands, necessitating the use of various architecture combinations. As a result, in order to meet the objectives, a correct design for the large data system is required. Nonetheless, while many distinct problems in big data systems are tackled, the concept of architecture appears being more apparent. The purpose of this article is to explore software designs for big data while taking architectural stakeholders’ interests into account and aligning them with quality characteristics. Cloud computing architecture provides an environment in which companies may safely create apps and employ cloud storage based on client needs. So now we have a comprehensive understanding of what Cloud Architecture is. In this post, we learnt what cloud computing is, the advantages of Cloud Computing infrastructure, cloud services architecture, and cloud services architecture parts. We intend to concentrate on software components for large datasets, taking into account design and implementation configurations generated from structural various stakeholder groups and aligned with quality qualities inherent in the development of diverse systems. The study questions are generated in order to determine which areas big data data is utilised in, the reason for embracing big data designs, and the current software structures for big data. Using our search approach, they found 622 papers. 43 of these have been recognised as primary articles related to their research. We retrieved data for chosen significant aspects of Big Data Software Components, such as existing architectural techniques to cope with the stated architectural limitations and quality traits, in order to discover various elements linked to the application areas.
According to Yassine et al. 2019: Internet of Things (IoT) statistics is a critical tool for gaining knowledge and supporting smart home technologies. Integrated appliances and equipment in the home automation generate a large quantity of data on users and how they can go about their everyday lives. IoT analytics can help in customising apps that assist both households and the ever-expanding companies that want access to local profiles. This article introduces a new interface that enables for creative analyses on IoT data gathered from smart buildings. Big data systems are suitable to data sets that are incompatible with the capabilities of general software devices and resources. The deployment of big data systems necessitates the use of cutting-edge technology such as cloud services, the internet – of – things, plus business intelligence. Lengthy expenditures in fields such as health, management, agriculture, defence, and entertainment are used to create such large-scale systems. The analytic capabilities of big data systems are heavily reliant on the high integration of dispersed software design, data management, and distribution. The key motivations for selecting the proper dispersed software, data processing, and distribution design of big data systems are scaling needs. Big data solutions have resulted in a full architectural transformation, such as magnitude and communicated systems that employ non-normalized systems and redundancy storage. Points of view are produced to focus on key quality features based on the area of use and the stakeholders, and obviously it depends on the sophistication of the described system, and over one perspective can be chosen. Architectural patterns are developed within the suitable context to tackle typical challenges in architecture. In perspectives, architectural principles, patterns, and restrictions are collected and expressed. To verify the technology and show relevant findings, they present a case study based on data collected from a genuine smart house in Vancouver, Canada. The results of the trials clearly demonstrate the value and feasibility of the suggested platform.
According to Hosseinian et al. 2018: Cloud computing has evolved to meet the demands of companies and to increase the amount and quality information data in which we can capture and analyse from a variety of sources including devices. Cloud technology has also transformed the software paradigm, transforming it into a customer paradigm in which cloud storage and applications are made available to the public. This application paradigm has altered the way we think about creating a cloud service. This chapter gives an overview of the underlying definitions, ideas, and conceptions that are currently lacking in the field. One of the extreme important innovation is fog computing. The infrastructure that is dispersed throughout a geographic location is known to as fog computing architecture. This organizational design focuses primarily on logical and physical parts, as well as software for appropriate network implementation. Fog computing design enables users to communicate in a flexible manner while also ensuring that storing capabilities are handled properly for such purpose of information management. However, it has been noticed that in the sphere of education, cloud computing architecture has grown in popularity because to its continuous integration capability. The tendency aims to enhance the importance of information and worth derived from data by developing technology for autonomous data analysis, visualisation, and usage, aiding machine learning techniques, and leveraging spatially analytics through innovative methodologies such as data cubes. Scientific proof research was originally effective in the field of medical, and similar techniques are now used in many other fields. Among the aims of scientific proof software development are constantly improved and measuring the extent to which best practises for software-intensive infrastructure are used.
According to Sing et al. 2018: The fast economic expansion of nations throughout the world has resulted in a commensurate increase in the related carbon footprint. In terms of law and policy formulation, various countermeasures have been proposed to minimise it. However, they have a short-sighted perspective in that they are primarily focused on the industrial and transportation industries, ignoring one of the major contributors to world emissions- the agriculture business. Cattle has the largest carbon footprint of any agri-food product, with beef ranches producing the majority of the emissions. The problem is more severe in poor countries, where the majority of the world’s cattle are kept, and landowners are less fully cognizant of re – sources to manage emissions from livestock farms. As a result, there’s any need to improve farmer knowledge and, as a result, adopt carbon footprint as a significant cattle supplier selection feature by slaughterhouse and processing, and integrate it as a regular practise in cattle purchase. Because cattle farms contribute the preponderance of the environmental impact, the conceptual approach would aid in reducing the environmental benefit of the cow supply chain. Furthermore, the vertical synchronization in the supply chain between farmers, abattoirs, and processors would be reinforced. The framework’s implementation is illustrated in the case study are as follows. We reviewed the current massive data application designs for several fields and published the findings to assist scholars and readers in gathering knowledge and suggesting future research topics. We may infer that huge data model building are used across a wide range of application fields. We discovered repeating common motives for adopting massive data technology structures, such as enabling analytical processes, increasing efficiency, enhancing real-time data analysis, lowering development costs, and allowing new sorts of services, such as joint effort.
According to Alam 2021: Cloud computing is a technology, used for developing new services & applications, data backup, analysing the data, blogs, website designing, audio & video streaming. In cloud computing, the processing of the data and its storage is done with remote servers also known as CLOUD SERVERS therefore this technology doesn’t need big & complex infrastructures. Since, the databases & software platforms are handled remotely; the personal computers remain free from computing tasks and storage of the data. The cloud computing provides a number of advantages such as cost reduction, disaster recovery, scalability, high efficiency, mobility, data security & data control. Architecture of Cloud computing includes two parts, one is Front end, and the other is back end. User uses the front end while the host manages the back end part. These both ends are connected with each other with the help of internet. The interfaces and applications are included in frontend part, which helps in accessing the services of cloud computing. The cloud services are managed on the back end by the company which offers these services and had the storing data facilities, security systems, virtual machines and servers. The main components of cloud computing includes Clients, server & cloud services. Other components are runtime cloud, storage, management, security, infrastructure and internet. Firstly, the client component is a frontend part; it provides the GUI (Graphic User Interface) which allows interaction with the cloud. distributed It is of three types mobile, thick or fat and thin, out of all thin is the most popular one. Secondly, the server or application is the software which is accessed by the clients. The servers are divided as central server system, distributed server system and data center. The servers which are usually in different places geographically but always work as a united group are known as distributed servers. The collection of servers at a place from where the application can be assessed through internet is know as datacenter. While the main central server manages the whole system such as traffic monitoring and client expectations to ensure that everything is going smoothly. The central server system uses Middleware software which allows different computers to connect and communicate. And the last is the cloud services which ensures and manages the services, as what kind of service needs to accessed in accordance with the requirements of the clients. There are 3 types of cloud computing, one is SaaS (Software as a Service), the other one is PaaS (Platform as a Service) and the last one is IaaS (Infrastructure as a Service).
According to Alnumay 2020: Software as a Service (SaaS) can be called as Cloud application services. It mainly requires an operating system, a software and a network is also needed. In this the apps are directly hosted by the individual provider. The user can directly access it by their own browser as SaaS applications us are directly runs through the browser and therefore do not need to download or install the applications. Some of the examples of Software as a Service are Salesforce dropbox, Hubspot, Google apps, Cisco WebEx, Slack. The Platform as a Sevice (PaaS) is also called Cloud Platform Services. This is little bit similar to Software as a service (SaaS) but the main difference in between is that the platform as a service gives a platform to create the software with the help of Software as a Service. The software can be accessed on the internet easily and do not need any particular platform. Some of the examples of Platform as a Service are Force.com, OpenShift, Magento Commerce Cloud Windows Azure. The benefits of PaaS is that they can develop, design and test an application directly. If increases the performance and flexibility of an application and also lowers its cost, at the same time it also increases the complexity, labour cost and security of the system. The Infrastructure as a Service (IaaS) can be called as Infrastructure application services or Hardware as a service. The Infrastructure as a service offers computer virtual or physical machines. It is usually responsible for operating data applications, middleware and also runtime environment. This service provider has the equipment and is also responsible for housing, building, running & maintaining the all. Infrastructure as a Service is usually costly and are mainly used in corporate businesses. Some examples of the Infrastructure as a Service- Cisco Metapod, AWS (Amazon Web Services) EC2, GCE (Google Compute Engine).
According to Habashi et al. 2021: The infrastructure provides the services on three levels, one is host level, other is application level and the last is network level. The infrastructure comprises of both software and hardware components like network devices, servers, software virtualization, storage and other important resources which are mainly needed in support of computing the cloud model. The virtual services eliminates or remove the physical computing machinery need like CPU, RAM and other data centers. In Infrastructure as a service (IaaS) the company runs the virtual servers, storage and networks, on the paid basis. In processing the system Internet is the main medium which connects and ensure the interaction between the front end and the back end. The storage is also an important component for the cloud computing. The software provides a lot of storage space in the system for storing and managing the data. Runtime cloud is also a component of cloud computing which gives off the runtime environment and the execution for virtual machines. The security of the system and the data is also an important aspect of the whole software, it is the back end which is already in-built in the cloud computing system. It executes the mechanism of security in back end part. To manage all the components of the system, like the application, storage, runtime cloud, servers, security, platforms, infrastructure and other problems the management component is used to establish and ensure a proper coordination in between all of them. Thus using the cloud computing based systems the companies can efficiently work on reduced cost and can also remove the extra infrastructure. It’s main advantage is that it impacts the creation in a positive way, the innovation and the collaboration and also the security ease of the data and the business sales.
According to Tang et al. 2017: We term it as a “smart company” because it uses cloud computing and technology of big data to enhance its services. These organization’s smart features come in a variety of levels, depending on how accurate their decisions are. Greater data analysis accuracy results in “smarter” companies. As a result, we are amassing vast amounts of information from the people, sensors, actions, algorithms, and the internet, which we call “Big Data.” Every year, the amount of digital data collected increases tremendously. Big data, as per, relates to datasets that are too large for traditional database software applications and tools to acquire, manage, store, and analyze. Data analysis is a crucial duty for any firm. Although analysis can reduce a vast quantity of data in such a smaller quantity of useful data, but we still need to acquire a large number of data. Across all fields of science, cloud computing has become a challenging subject. Many solutions have now been presented in scientifically big data that overcome big data difficulties in the fields of the life sciences, material sciences, education systems, and social networks. Cloud computing mean the internet-based services such as database, storage, software, analytics, as well as other platforms. Any service which can be provided instead of being physically near the hardware qualifies. Netflix, is an example, employs cloud computing to provide service of video streaming. Other example includes G Suite that is completely cloud-based. The front-end as well as back-end of cloud computing architecture are separated. A network and the internet connect the front-end as well as back-end. Front-end basically gives the necessary apps and interface for such services based on cloud. Client-side apps, like web browsers like Google Chrome or Internet Explorer, make up this system. The element of front-end was cloud infrastructure. Data storage, servers, virtualization software, as well as other hardware and software parts make up cloud infrastructure. This also gives end-users the graphical UI via which they may do their jobs.
According to Odun-Ayo et al. 2018: While if we talk about back-end it is in-charge of keeping track of all the programs that operate the application at front-end. This has a significant number of servers and data storage systems. It’s a critical component of the entire cloud computing architecture. Back-end cloud architecture includes following components service, application, storage, security and management. When dealing with large amounts of data, the cloud computing seems to be the ideal option. Yet, cloud computing was in its infancy, and there are still some important difficulties to be resolved. When huge data costs clients’ money as well as a system failure could destroy a business in the era of digital work, moving apps and databases out of a traditional paradigm to the clouds is difficult because migration toward a system of cloud computing is challenging; it necessitates the redevelopment of programs, data, as well as the adoption of efficient programming methods to rescue resources and expenses, returning information to any IT department becomes challenging; connections are made via an insecure networks, like the Internet, cloud provider administrator clients may have access to peoples data; and the location of the data store is not visible to customers. We don’t have a standardization for cloud computing or a common cloud architecture. This leads to a slew of problems, including disparate architectures, difficulties migrating data and applications to certain other cloud suppliers, a lack of flexibility within cloud computing systems, as well as a lack of a solid Service Layer Agreement (.SLA) ensuring customer satisfaction. Customers that utilize the cloud must have an agreement including one or even more cloud suppliers (typically only one), or they must be using the APIs, OS, middle-wares, and interfaces provided. Data and applications rely on platform and are hosted on cloud provider infrastructure. This reliance on cloud computing services has a number of drawbacks.
According to Stergiou et al. 2018: In systems of cloud computing, security seems to be a key problem. Cloud features like a common pool of resources or multi-user offer a security risk since the pool of resource is used by users, exposing users’ privacy and security to others. Other key security problems based on Internet access to the cloud include unsecure connections to the provider, security of network access, security of Internet access, as well as cloud provider’s user security. An internet – based storage system that allows many clients for access and store data. Cloud storage has often been installed in one of three configurations: private cloud, public cloud, community cloud, and hybrid cloud that combines all three. Cloud storage must be agile, adaptable, scalable, multi-tenant, and secured to be effective. Modern cloud computing services (Amazon EC2 is the example) may not be capable of providing cost-effective functionality for Applications of HPC when compared to tightly-coupled hardware like Grid Computing and Parallel Computing system, according to certain research. A vendor might supply cloud computing software that allows IT teams to focus upon software creation instead of hardware upkeep, security maintenance, disaster recovery maintenance, software upgrades, and operating systems. In addition, if such department of IT implements the cloud computing systems in their business, it may be able to assist them in handling large amounts of data. Cloud computing system’s architecture is unique towards the entire system as well as the requirements of every component or sub-component. Big data may be analysed, designed, developed, and implemented using cloud architecture. In cloud computing system, companies deliver services using service layers. Infrastructure as a Service or IaaS, Platform as a Service or PaaS, Software as a Service or SaaS, & Business Intelligence or BI were the four business service levels, with another service layers allocated to the primary service layers, like Data as a Service (DaaS) given to a IaaS layer.
According to Ahmadi and Aalani 2018: The numerous advantages of cloud computing were being recognized by a growing number of tech savvy enterprises as well as industry leaders. Companies are also adopting this new technology to operate their businesses more effectively, provide better service to their consumers, and substantially raise their total profit margins. Given the obvious direction wherein the business is heading, it appears that there was not a better moment using your mind in the clouds. Cloud computing system is a phrase that has become increasingly popular in recent years. Also with exponential growth of big data usage which has accompanied today’s society transition further into digital twenty-first century, organizations and individuals are finding it increasingly difficult to maintain every of their critical information, programs, and systems up to speed on in the house computer servers. The above problem seems to have a solution which has been available almost as the internet network, but it has only lately received significant corporate use. Cloud computing works in the same way as internet based email clients, allow users to get access to all the functions of the system and data without requiring to maintain the majority of the systems on their particular computers. In essence, the majority of individuals are currently using services of cloud computing even without recognizing it. Cloud-based programs include Google Drive, Gmail, TurboTax, and even Instagram and Facebook. Users transmit their personal information toward a cloud-hosted servers for each of these service, which saves it for later reference. The benefits of cloud computing includes cost savings, 20 percent of businesses are worried about initial expense of installing a cloud-based servers due to the high cost of relocating to the cloud computing. However, individuals seeking to assess the benefits and drawbacks of adopting the cloud must weigh more than simply the initial cost they must also consider the return on investment. Easily access to company’s data when you establish the cloud computing it will save money &when the time comes to start up of project. Usually cloud-computing service you may pay as work goes on, which is great news for anyone concerned about spending for features they don’t want or desire.
According to Sharma et al. 2017: When implementing a solution of cloud-computing, several businesses are concerned about the security. It is cloud host’s full time responsibility to monitor the security closely,that is more effective than an in-house system that has been around for a long time, whereby an organization should break its resources amidst of different type of the IT problems, security is would be one of those. Whereas most organizations prefer not to discuss the risk of internal data thieving, the fact is whether an alarmingly high proportion of the data theft occurs within the company and is committed by employees. The company can only concentrate on a few things at a time to distribute across its several tasks. If your current IT solutions cause you to spend a lot of time as well as energy on the computers, it’s time to upgrade as well as data-storage difficulties, you won’t be allow to concentrate on achieving company goals and satisfying customers. Companies have a lot more time to devote to various aspects of their operations which directly influence bottom line when you depend on some outside organization that operate IT hosting as well as infrastructure. While comparing to the hosting upon the local servers, the cloud gives organizations with significant freedom. Moreover, if wanted services on based on a cloud, instead of requiring a complicated update to the IT infrastructure, bandwidth may be able to supply it quickly. Cloud Computing enables smart-phone as well as computer access to business data. For better work-life balancing, you may use cloud continue providing easily accessible data to salespeople who work on a freelance basis, travel, or a telecommuting employee. As a result, it’s not unusual to find companies that place a high premium on employee happiness. Your company can easily scale up and reduce its operation or storage needs to meet your requirements, giving you greater adaptability as per your needs. Rather than purchasing and installing pricey updates, a service of cloud computing supplier may be able to do it for you. Using the cloud enables one to focus on running your business rather than bothering about technology.
According to Hu et al. 2017: Business continuity management requires you to keep your information and systems protected. Keeping data saved inside a cloud guarantees that it backs as well as preserved in a safe and secure location, irrespective of whether you face a power outage, natural disaster, or any other crisis. Getting able to rapidly access data helps you to continue doing business normally, minimizing downtime as well as lost productivity. Collaboration is made easier using cloud computing. By a cloud-based network, team members may simply and securely access and share data. Several cloud-based systems even offer collaborative social areas to link employees throughout your company, boosting participation and involvement. Without the need for a solution of cloud computing, collaboration might well be feasible, but it’ll never be effective or easy. Few factors are as damaging to a company’s growth as low quality or inaccurate reporting. All papers are saved in one location and in the same format inside a cloud-based platform. You can preserve data consistency, eliminate human error, or might have clear records of any modifications or changes if everyone has access to the correct data. Managing data in divisions, on the other hand, might result in employees storing various documentations by accident, resulting in confusion or diluted data. The data remains inextricably linked to a office systems if your company does not indulge inside a solution of cloud-computing. It may not come in to sight as a problem, however if the local hardware breaks, you could lose all of your data permanently. There is nothing more inconvenient than waiting for system upgrades to be downloaded when you have a load on your schedule. Rather than having a department of IT to execute a manual organization upgrade, cloud-based apps constantly refresh as well as update itself. It saves money and time for IT personnel that would otherwise be spent outside on IT consultancy. Many systems require upgrading or maintenance to function properly. This frequently results in brief outages in system management and traditional infrastructure. However, one advantage of cloud computing would be the system is generally administered across several systems, reducing or eliminating necessity downtime full-system. Finally, cloud computing has the advantage of ensuring that the systems were monitored 24 hours a day, seven days a week. Traditional staff often demand days off, sick days, vacation time, and aren’t accessible 24/7 a day, making this tough to reproduce on-site at any firm. To supervise systems and infrastructure, cloud computing businesses frequently have around the clock staff and management.
According to Zanoon et. al. 2017, the use of information technology to communicate in various ways generates large volumes of data. Such information needs processing and storage. The cloud computing is a type of online storage paradigm in which data is kept on a number of virtual computers. Big data processing is a new computer issue, particularly in cloud computing. Data processing involves data collection, storage, and evaluation. Many concerns arise in this regard, such as what the link among big data and cloud computing is. So how is large data handled on the cloud? So how is large data managed on the cloud? The answers to these concerns will be explored in this article, in which cloud and data computers will be investigated, as well as the link between them since terms of security and difficulties. We proposed a name for big data as well as a paradigm that depicts the link between big data with cloud computing. Cloud technology is a paradigm in technological growth, since technological advancement has resulted in the rapid expansion of the digital data society. This result in the phenomena of big data, and the rapid rise in big data may pose a dilemma for the advancement of digital information age. In this research, the author wants to discuss the relationship between cloud computing and big data through various hypothesis and analysis. The internet of things is a new principle of the Web system that connects information exchange between several parties, including smart devices, handheld platforms, detectors, and also other where it is regarded effective interaction across all orders of design because it can quickly utilise applications, process and analyse information to make decisions. Objects, gates, internet infrastructure, and cloud infrastructure are all represented by the framework. The versatility and speed of cloud computing environment can help Internet devices.
According to Manogaran et. al. 2017, the main purpose of the researcher was to use of big data analytics in the field of healthcare with the use of cloud computing and internet of things, wearable technologies now play an important role in a variety of contexts, including continuous healthcare monitoring of persons, road traffic, meteorology, and home automation. These devices continuously create a massive quantity of data, which is stored in the cloud. This chapter offers a Network of Things (IoT) architecture for storing and processing large amounts of sensor data (big data) for healthcare applications. The new structure is divided into two major sub-architectures: MetaFog-Redirection (MF-R) and Clustering & Choosing (GC). Although cloud computing allows for massive data storing, it must be handled by powerful computer systems. Scalable algorithms are required to analyse the massive sensor data and discover relevant patterns. To address this issue, this chapter presents a scalable Middleware logistic linear regression for processing such massive amounts of sensor data. Apache Mahout uses scalable logistic analysis to determine huge amounts of data in a decentralized way. This chapter processes sensor data provided by connected medical devices using Apache Wild mustang and the Hadoop Consolidated File System. Technological improvements and cost reductions in medical equipment and illness diagnostics have hastened the use of cutting-edge technology in a variety of institutions. The advantages of receiving engaging or cognitive medical services based on information retrieval are continuously expanding. The proper categorization of various illness and disability is critical in assisting clinicians in carrying out disease-specific treatment plans. Traditional illness classification techniques, on the other hand, typically follow naïve procedures based on partial disease knowledge, and may fail to further categorise a medical clinical signs at alternative treatment phases. So cloud computing with big data also plays a major role in not only save lives but also advancement in healthcare system.
According to Garg et. al. 2019, In this research paper, the author with the explosive growth of internet of things (IoT, edge computing, and 5G throughout recent years, a massive amount more data from multiple sources has been created from varied uses with in smart city environment. As a result, advanced ways for processing such massive amounts of data are required. ITS, one of the key components of smart buildings, has given rise to a plethora of applications such as environmental, entertainment, actual traffic control, and so on. However, the scientific community is concerned about its safety, speed, and reliability. Existing alternatives, such as phone systems, RSUs, and mobile cloud computing, are far from ideal since they rely heavily on centralised design and incur the expense of extra infrastructure development. Furthermore, traditional data management methods are incapable of properly managing massively scalable data. To address these concerns, this paper offers an improved automotive communication style in which RSUs are substituted with edge computing systems. The Quotient filter, a statistical graph database, is then used to create safe V2V and V2E connectivity. In conclusion, a security monitoring paradigm for VANETs coupled with edge of the network modules and 5G technologies has been created to improve terms of computational capacities in the current smart city environment. It’s been empirically established that using edge nodes as an intermediary connection between the car and the cloud decreases accessible to the users and avoids bottlenecks in the backhaul, allowing for rapid choices regarding traffic scenarios in the vehicles’ geographic region. The suggested approach surpasses traditional vehicle models by offering an energy-efficient safe system with the least amount of delay. For AI-based methods, the proliferation of linked IoT devices poses a significant data challenge. The reaction speed demanded by such devices demands the processing of IoT data at the edge, yet the edge generally lacks the capacity to train AI models. We offer a design for AI algorithms that retains the benefits of both periphery computation and computer processing. We talk about how strategy. This strategy may help improving and enhance this design. To detect occurrences compromising pipeline safety, we evaluate case histories using a sophisticated pipelines surveillance system based on fibre optic instruments plus sequential supervised learning. A functional prototype was built in order to scientifically monitor the efficiency of real – time processing in the identification of 12 unique events. These trial findings show that a city-wide design of the project is feasible in the future.
Research Methodology
This research mainly deals with the concept of cloud computing in conjunction with big data, and cloud computing architecture. Since platforms of cloud computing are not as same as the virtualized or physical computing platforms, it is necessary to look into and understand the basic opportunities and limitations of the cloud environment while creating the solutions. Methodology of cloud includes four main phases, the first is the assessment of organizational readiness which involves the competency of staff, structure of organization and the cultural considerations. The second is Review of architecture which involves inventory of all network, storage and components of computing, and the assessing the managing and monitoring capabilities. The third is the planning of cloud computing which involves the planning on premise, planning off-premise and the hybrid (Odun et. al. 2018). The fourth is the transformation of cloud which involves the planning the migration ideas and identifying capturing value and the early success. In the research we focused on many succeeding factors involving the planning, implementation, execution and the transformational processes as planning can directly produce early ROI programs, implementation allows planned IT alignment along with their business, transition of cloud can directly be adjusted in a CAPEX or OPEX budgets, and their modelling organization is important for collaboration and the results gives the overall differentiation.
In this research, descriptive, predictive analytics approach is used, as descriptive analytics deals with the examination of previous or older data to find out the trends and then provides the managing reports as it is helpful in forecasting the future behaviour. On the other hand the predictive analytics evaluates the present and the previous data for future forecasting. The research includes several steps that needs to followed while architecting the cloud computing in Big data like developing a modular functional architecture needed for cloud solution, then the operational model development for functional components of cloud solution like infrastructure and platform services, then performing the analysis of fit-gap for the components, which determines the requirements of computing resources for functional components, the backup requirements, managing system requirements, availability of components and scalability, performing requirements, bottleneck & other failure points of all functional components. Since the data analysis are used in various sectors such as healthcare, business, banking, transportation, sports, energy etc. the different analytic tools for data, algorithms, large data and supercomputers are analyzed for providing the proper meaningful & insights for end-user. The data then is converted to the formats such as statistics, graphs, patters, etc. for creating the report. The analysis of data helps the company to understand the preferences of customer, pointing out the opportunities for revenue, and more effective demands which will make them to work on the products and services that results in the raised profits, growth and competition in market. Requirement for identifying the short comments of the process data is needed for improving the limitations and challenges for collecting the correct and accurate data from the number of different sources (Odun et. al. 2018). Duplication of data is also a major concern since the data is taken out from a number of sources that can directly lead to inaccurate data analysis and the results, and there are possibilities of receiving the inconsistent data or the heterogeneous data as the standards of the collected data in different countries and States are numerous, there are chances that the data can be inconsistent which makes the comparison of data sets difficult for the services.
Service providers of cloud infrastructure are giving a lot of services that combines a number of diversifying components and resources like network, storage and computing. But there is a lack of standard description and systematic discovery’s inadequate research and the selecting methods faces difficulty in selecting the right services for client and users. The first method is feature model, which is used for describing the high configurable features of the services of cloud infrastructure. Second one is on the basis of cloud infrastructure’s description the selection method and systematic discovery are proposed. Feature model technique of automatic analysis verifies the validity of the models and does the service matching and the demand models matching. With these method we can directly determine the metrics of critical decision and the other corresponding methods of measurement for the infrastructure services of cloud, where the objective & subjective results are added to get the decision metric’s weights. After that the matching instances-are ranked with their overall evaluations. The experimental results shown that the methods such as proposed method has greatly improved the efficiency and accuracy of the discovery & selection of the infrastructure service of cloud. In 1990 Kang et al, gave domain analysis method that is feature oriented also known as FODA. It was used to organise and capture the requirements of the software in different periods. Feature models are usually used for representing the functional system and the non-functional characteristics feature models were used to represent the structure of an organisation and the characteristic’s internal relations.
In the academic researches there are methods which discovers and selects an infrastructure as a service that is divided into different categories such as Semantic technique based on description & matching methods for Iaas. This technique used the web service modelling ontology for the virtual units and the virtual appliances and present semantic method for the demand and supply on the IaaS. The method of Discovery on the basis of semantic matching is only be matched with the providers and not with specific instances of Iaas. The FM is used to describe the infrastructure service as complete structure and in an accurate manner which can then directly use the technique of automatic analysis of FM for searching the instances which can be matched to get an optimal solution (Manogaran et al. 2017). The second technique is QoS evaluation based selection method for Iaas which includes the evaluation and comparison of the cloud services on the basis of cost, accountability, performance, security, usability, agility, assurance, and privacy by a CSMIC ( Cloud Service measurement index consortium) of University of Carnegie Mellon. The third technique is the FM based selection and description methods which is based on the variability modelling as the authors initially give a simple model domain and didn’t it gave the copying method for the heterogeneous expressions. In this research we have described the domain model and semantic model for infrastructure service in a standard manner and proposed the selection methods and automatic discovery.
There are four roles that are needed to be managed in the cloud architecture are IaaS Provider, User, Broker and MTCCAs. The first is the IAS provider that publishes the service information on their website and chooses to do certification service and/or registration in collaboration with MTCCAs. MTCCA’s like CloudScreener, CSA, CloudHarmony, Cloudorado performs the testing, monitoring, comparisons and security certifications.
The technological processes that have an influence over the increasing ethical issues comprises of privacy, security, performance, metrics and compliance. The security and privacy is needed as there are times when there can be Unauthorized access is done to our sensitive data by any hacker or by cloud service provider itself and / or any third party we may never know who did that and how can our data be abused, so there must be proper security and privacy systems should be there to avoid such issues. The cloud computing service needs to comply group of standards in accordance with the applications, for developing and maintaining the processes of system. On the other hand the performance of services are mainly stipulated with the SLA (Service Level Agreement). In the situation of violation of SLA performance metrics, there are penalty system for compensating the customers.
This research gives the descriptive findings and methods of selection in in cloud. The standard methods for description is designed that uses a structured way for describing and tagged configuration of the cloud computing (Manogaran et al. 2017). These methods help in overcoming the issues related to the existing methods. Using these methods the accuracy of service is improved and the result ranking is more reliable and objective. The combination of multiple services helps in meeting requirements of applications better for example the e-commerce globally. Group of different Iaas’s are used that result in effective dispersion of users request which helps in reducing the pressure of the system and the experience of the user is also effectively improves. There are some applications that needed to be deployed for the formulation of different IaaSs like the application of big data analysis and the medical related applications that has to collect actual data from different countries for the processing and analysing. There will be time when the laws of some countries will be strictly prohibited the moving out off the original data without purchasing the IaaS that is present in that particular licensed area. Hence, a strong and suitable approach is needed for the selecting the best system for data composition on the basis of user need. Also and acceptable security compliance performance privacy in all the layers of it should be done not only to fulfil the terms and conditions of an agreement but also to provide the reasonable ethics for cloud computing services.
Systems of Big Data Analytics in the Cloud
We will describe here some of the basic tools we will be using like such as MapReduce, Spark, workflow systems, and NoSQL database management systems.
1) Map Reduce
MapReduce is used for large scale data processing.
2) Spark
It’s a apache framework for big data. It’s basically used for big data processing .Its keeps data in RAM for better performance .Used in iterative machine learning algorithms. Spark has only one limitation that it does not store the data in distributed format like Hadoop does here cloud comes in the picture. We can run spark on multiple nodes of cloud nodes like amazon s3 storage.
3) Mahout
Apache Mahout is framework which is open source and provides implementation of machine learning algorithms which accepts big inputs .These algorithms provides filtering , classification and clustering .These algorithms can be used with Hadoop as well as spark .But spark is more preferred because of its performance .
4) Hunk
A enterprise data analysis platform. Used for exploring, analysations and visualization data in Hadoop and databases like NoSQL. It’s used High level languages to perform analysis from unstructured and structured data sets (ElKafhali et. al. 2021). Its crucial parts are Splunk virtual index. It can decouple request from data access and analysis layers so that it can be routed to different data stores. Hunk is used on top of Hadoop data for big data application.
5) Sector and Sphere
It’s a cloud framework used for data analysis of large sets which are based on geographical distributed sets in which data will be processed in concurrency i.e parallel. Sector is a storage service .whereas sector is a distributed storage service which can be deployed over WAN and allows for ingestion of large data sets from any location.
6) BigML
Its SaaS (software as a service) for creating predictive models from given data and also used classification and regression algorithms. The models are presented in decision trees. These trees can be dynamically visualized in bigML interface.
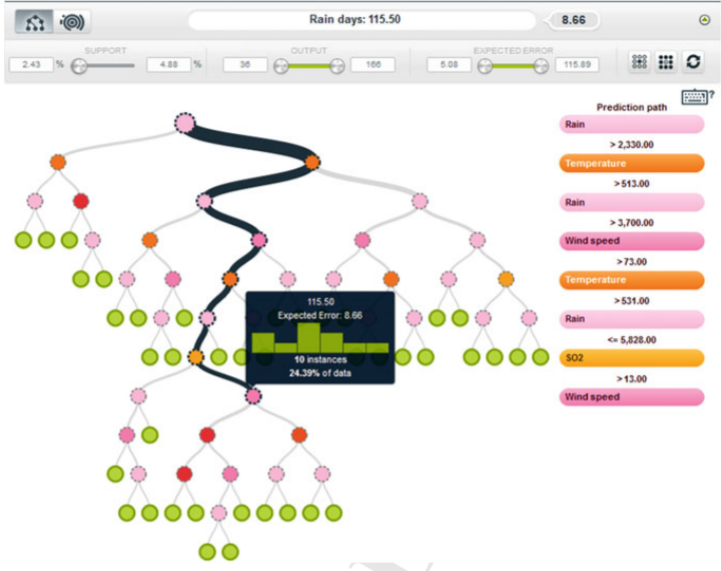
This above figure is one of the examples of prediction model for air pollution on BigMl
Extracting and uses of predictive models in bigML comprises of multiple steps as follow:
- Model Extraction and visualization – From the given dataset, the system generated the np. Of predictive models, where user can also choose the level of concurrency.
- Prediction Making – A single model or multiple models from different dataset parts can be used to make new predictions on new data.
- Models Evaluation: BigML provides evaluation tools for the predictive models gathered.
7) Data Analysis workflows
A workflow is a set of steps executed in a series, these steps can be activities, events or task. For example like a workflow for pre-processing, analyzation, post processing steps.
Some of the available workflows framework
- Data mining cloud framework (DMCF) – It allows users to create, design and execute data analysis workflows on cloud. Its supports single task application, parameter sweeping application and workflow application.
Its architecture consists of- Data Folder
- Data Table
- Task Queue
- A pool of Virtual computers
- A pool of virtual series
- App Submission
- App monitoring
- Data management
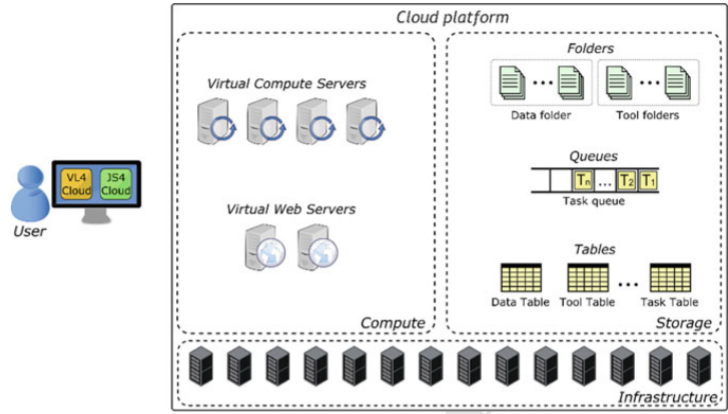
Above figure shows the architecture of DMCF
DMCF architecture is a reference architecture to be on different cloud systems. Its first implementation was carried out using Microsoft azure cloud platform. In DCMF, one virtual web server runs continuously in the cloud, as it serves as user front-end.

Above Example of data analysis application designed using VL4Cloud
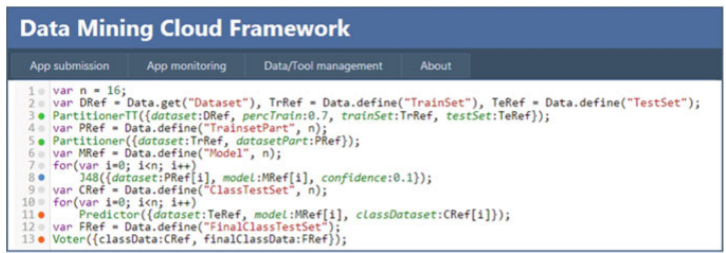
Above is an example of data analysis designed using JS4Cloud
In JS4Cloud, javascript is used for defining workflows that interacts with elements and data using three functions:
- Data Access
- Data definition
- Tool Execution
After submission of workflow code, an interpreter translates workflow into series of tasks based on existing dependency.
Analysis
This study analyses the proper development and functioning of the cloud computing system and also the constantly improving and measuring methods for providing the best services to the users. It is the paradigm where resources like computers, bandwidth and storage can be taken on a rented basis. Its major advantage is its convenience and elasticity, here convenience stats the fact that user does not need to deal directly with the problems relating the owning and maintaining of the resources directly while the elasticity means the rent paying ability for the resources that are exactly needed. The data sequencing archives are huge and are growing rapidly. The cloud computing had become the important part in enabling the efforts for analysing and reanalysing the large amount of sequencing archived data. It is becoming the venue for introducing the bigger global collaborations that benefits with the holding data ability securely at the same location. Genomic research funders are getting aware of cloud computing and its advantages day by day and thus are starting to allocate the funds for creating the resources based on cloud services. The clusters of cloud computing can be configured with the measures of security for adhering with the privacy standards like the databases of phenotypes and genotypes.
Since the major issues in cloud computing is related to scalability, performance, security, privacy and availability are their, the basic need of identifying and reducing these issues are concerned as to how to design the system of cloud computing, its infrastructure to be secured and available easily. According to the study, the cloud computing is the ideal option but still there are drawbacks which are needed to be overcome to provide better results for the user. The descriptions of demands and services makes a route for automated service discovery. The searching process for the services satisfies the demand of the user directly from the matching demands and supply on the system (Zhang et. al. 2017). To supply matching demand on IaaS, feature models are required for the analysis that analyze automatically without any manual involvement. It is not possible to select an artificial method for analyzing the service models, therefore an automation procedure is required. The analysis can be marked as a process of black-box, involving the feature models and other specific operating parameters as an input, which can be retrieved and the output of the results on the basis of the criteria for the analysis (ElKafhali et. al. 2021). The analysis includes the correctness of data and syntax, then judging whether the conflict is present or not, and verifying the configuration of the input product whether it is valid or not.
While performing the analysis on a service model, it is essential to determine and check the validity of the model by semantic conflicts and syntactical correctness. The checking of semantic conflict are usually prone to introduction when the complex constraints are created on attributes and features. The service model of cloud computing includes the judging of syntactical correctness. In this we have to select a language for expressing the model for example XML or any other custom language (Zhang et. al. 2017). We need to comply all the information with adequate language syntactical constraints while creating the text file of service model.
The maximum advantage of cloud computing can be taken by aiming the hundred percent provisioning automation, which is the reason for the installation of the cloud as it will improvise the speed of computing power. Putting it in check points for authorization can slows down its process. The catalogues of cloud contains the list of different type of powered compute and the application needed with them that the uses want. It helps in reducing the supporting cost and protects its organization. And it also automate the patches deployment and fixes it to the systems that are deployed in cloud (Singh et al. 2018) . Cloud computing system is also cost reducing system and makes the things to happen. Hence, it does not required to wait for months or weeks for getting installed a new compute power. Hence the users have a lot of compute power and the control over how they can access the power. Without IT the cloud is just another project that has only limited value. The vision of cloud and its benefits can make the realization that the organizations need to own the cloud. The management needs to know the advantages prior in the development phase for ensuring the true & achievable vision of cloud computing and the changes in the concept are needed to be assessed and are needed to be accepted widely.
The categorizing analysis level is used for considering the cloud computing system to focus on the global, national, organizational, and individual aspects. The most number of articles related to this study is found to be of general categories. Articles do not specifically focuses on research and seeks to give only basic information about cloud computing. On the other hand not only articles are focusing on general aspects there are a lot studies that focusses on organizational levels in comparison to national or individual level studies. This indicates that the information system are still recognized as an important data in the organizations. Despite acknowledging the study, we believes that the research on the topic cloud computing will create major awareness at a macro level i.e. at a national level and will also support the policies that are favourable for the cloud computing system. The global and national level valuable and precious insights will provide and foster the legislation worldwide towards adopting the cloud computing ease as well as its use.
The sequencing of next generation has their major strides from the past one. Researches based on the large amount of sequencing data groups are increasing in number continuously, and the archivs of public fort the raw data sequencing have been multiplying in size in every eighteen months. Data leveraging needs the researchers for using the computational resources on large scale. The solution for storing large data, users rent the computers and storage, and this is gaining the hype in the genomic research.
FUTURE SCOPE
Talking about the future aspect of cloud computing with big data usage, we can predict that this industry will at an immense growth. The distribution of IT assets through the internet is known as cloud computing. The key aspect of cloud services that distinguishes it from the competition is remuneration pricing. Cloud technology is now employed by companies of all sizes. Firms utilise this technology for a variety of areas such as data recovery, email, data analytics, and so on. Cloud technology has had a tremendous influence on corporate operations and numerous forms during the last ten years. This service is continually changing, and the majority of additional wealth features being created, as well as the data quantities, is rapidly increasing.
Cloud technology has a plethora of options in the near term and is now an inexorable sector of growth; there’s many fascinating projects you may work on (Aazam et. al. 2017).
The Upcoming Relevance of Cloud Computing:
Cloud computing may play a major part in the growing new era of technology, the millions more options opening up as the development of cloud services takes off. The most essential reason for cloud computing’s future success is that it is highly useful. As according research Firm idc, an advice form and worldwide research inside S&P Key Industry Data, the cloud technology market in India would expand at a growing at a cagr of 15%.
Top 3 areas whereby cloud hosting may be used that will thrive in the future:
Data Backup: Using cloud services, we may store files, pictures, movies, or audio recordings on the internet and access them via an internet access. Because cloud services must guarantee security, they also provide a variety of proper backup apps for recovering deleted information.
Education: In the midst of the present epidemic, cloud storage has emerged as a critical instrument in the school system. Cloud computing provides students with a variety of student attendance portals as well as many online distance learning tools, and are in high demand right now. This educational approach will only grow in the future, providing a wide range of opportunities in the context of cloud computing (Noor et. al. 2018).
Entertainment: Along with schooling, music is an evergreen area that will not go away in the near future. Many companies in the music business employ a multi-cloud approach to engaging with its target market.
Big Data and Cloud Computing are essential in today’s corporate landscape. Big Data delivers insightful market intelligence. Cloud computing allows us to store the data to make it widely available. It’s similar to having virtual space for storage available to consumers.
In reality, these two words are rapidly being used interchangeably. Such massive data sets can’t exist without data storage. At the very same time, this type of data represents a massive source of revenue for the internet. And, when combined, they offer a treasure mine of career prospects to anyone who is interested in the subject.
We are seeing an expansion of content throughout the online as the cloud continues to develop. Social media is a whole new world, where both advertisers and needs of the customer create massive amounts of data on a daily basis. Businesses and organisations generate data on a regular basis, which could become challenging to manage over time. Take a peek at all these Big Data generation figures over the previous five years:
- Every day, 2.5 Quintillion bytes (2.3 trillion gigabytes) of information are produced.
- By 2022, 40 Zettabytes (43 trillion gigabytes) of data will be produced.
Most businesses in the United States must have had at least 100 Terabytes (100,000 Gigabytes) of data saved.
These massive amounts of data pose a problem to the cloud infrastructure. How can the substance of this data be managed and secured rather than just piling it?
Cloud computing and big data appear to be an excellent match for this. They come together to create a system that would be both flexible and adaptable to big data and business intelligence. In today’s environment, the analytical edge will be quite valuable (Buyya et. al. 2018).
Newer technologies, such as Apache Hadoop, are made it feasible to examine extraordinarily vast and diverse data sets with more precision. This adds a lot of value to businesses while also aiding with company growth. The ease of access and economic viability of cloud technology in processing these massive volumes of data has assured that Big Data and Cloud Computing are here to stay. As the usage of these technologies grows, so does the demand for skilled people. Cloud computing enables safe, accessible, and cost-effective virtual archiving for huge amounts of data so that every one of the data in cloud is also now useless unless it is examined by something. As a result, skills in analysing these databases are in high demand. IT experts with data analysis training can leverage the potential of Big Data for businesses and are in high demand. Data scientists and analytics experts are in high demand.
According to the graph displaying industry trends online Job or other job sites, career possibilities for Analytics and Cloud Technology are increasing at the same rate.
Cloud designs began by emulating recognised concepts from on-premises infrastructures. This led in very many IaaS-based systems in which the computers were simply relocated to the cloud as vms but continued to run the very same applications and so used the same structure.
Although there is nothing fundamentally wrong with this strategy, it has a significant drawback: just a tiny portion of the advantages of cloud computing are utilised since you are not creating for such cloud, but adjusting to the sky.
So all the above mentioned points will play a great role in contributing towards the cloud architecture with the inclusion of big data, as cloud architecture will not only play huge role in healthcare but also other industries like machinery, automobiles, manufacturing, technology and many more.
CONCLUSION
To conclude this, we can clearly say that in cloud computing, big data plays a major role they must have a relationship between each other.
Commonalities between big data and cloud computing:
The cloud services infrastructure is made up of a number of access points and a service provider. Large data is generated on both ends, as the user gathers data and generates big data while interacting with technological tools. The solution provider’s job would be to save, store, and analyse large data at the customer’s request, therefore cloud computing offers huge volume of data (Zhang 2018).
Data, either little or large, involves storage, computational, and privacy; however, the amount and ability of data needs vary according to the amount of the data; thus, cloud technology must offer storage, preparation, and information protection for big data in its ecosystem. As the network operator secures and maintains data, the cloud is scalable and employs expertise in various data analysis techniques including security rules.
Cloud computing offers security based not even on storage capacity but on the provision of security and safety for tiny and large data sets. The phone company ensures the total confidentiality of all user data and limits access to just authorise users. As a result, authentication mechanism and password protection must be given for information strategies proposed capabilities based on user requirements. A simple software system that simplifies and ignores numerous underlying complexities and procedures allows users to connect to the networks in these facilities (Chen et. al. 2018).
Cloud computing cuts the cost of data processing and analysis for the customer by utilising multiple geographical computers and virtual server technologies. The network operator must guarantee that the instruments are readily available and limited by an incorporated and recorded entry mechanism for reference in the future. Cloud computing enables its use of increased programmes and software independent of the performance of the user’s equipment, because it is dependent on the quality of the computer systems rather than the available money of your device. Cloud computing is classified as a decentralized system since it is dispersed across geographical boundaries. One example is the general cloud, in which resources are spread throughout.
This allows the user to have faster access to the data. As a result, cloud storage is focused on resolving the issue of geographical divergence between devices and systems. It also allows numerous users to share a central database and assets like internet pages, documents, and other material assets. Cloud computing is distinguished by its capacity to resist failure by delivering resources in the lack of constituent defects. Because the cloud is regionally scattered, there is a significant possibility of mistakes. These occurrences highlight the need of failure acceptance strategies in achieving reliability. All of these aspects illustrate the link among cloud computing, as they demonstrate the critical requirements for the on-going expansion of big data while also providing an adequate environment for compete with large data (ElKafhali et. al. 2021).
What is the relationship between the cloud computing and big data? The answers indicates their connection. This is accomplished through the cloud computing capabilities that manage large data, the resources supplied by cloud computing, and also the capacity service that provides services to so many clients by constantly setting and resetting the different physical and digital capabilities upon request. Cloud computing provides access to the information resources located throughout the world from any location by utilising a (public) cloud to provide those sources with better accessibility to storage.
The cloud computing architecture can support small and large data volumes by expanding the solid hardware. A cloud can scale to accommodate large quantities of data by splitting it into pieces, which IAAS does automatically. Expansion of the environment is a significant data demand. Cloud computing offers the benefit of lowering costs by charging only for the utility of the assets used, which aids in the development of big data. Big data is also seen to necessitate flexibility. When we really need extra storage for data, the cloud platform may dynamically grow to meet our storage requirements whenever we need to manage a high number of virtual machines in a brief span of time. Cloud computing provides benefits and advantages to big data by develop and learn more accessible, decreases the cost of resource usage determines the price, and reducing its use of solid gear needed to handle large data. Both big data as well as the cloud seek to improve a firm earnings while lowering investment expenses. The cloud lowers the cost of operating local programs, whereas big data lowers capital investment by driving more cautious strategic choices. It seems only logical that all these two principles, when combined, give more value to businesses (Odun et. al. 2018).
Big data and cloud computing have been researched from a variety of perspectives, and that we have determined that their connection is mutually beneficial. In the realm of decentralized network technology, big data and cloud computing create a complete model. Because the link behind them is centred on the item, store, and computing as a common element, the expansion of big data and their demands is a factor that encourages cloud provider for continuing improvement. The commodity is represented by big data, and indeed the container is represented by the cloud. The capacity of cloud computing is important to big data. Big data is interested with cloud computing’s capabilities. Cloud computing, on either hand, is concerned with the kind and source of large data. A model was created to depict their connection based on the relationship among them. Their complementarity is summarised. Cloud technology is an ecosystem of flexible distributed energy resources that employs advanced data tracking and communication techniques while lowering costs. All of these features demonstrate that cloud computing and big data are inextricably linked. Both are making significant development in order to stay up with changes in innovation and users.
References
Aazam, M., Zeadally, S. and Harras, K.A., 2018. Fog computing architecture, evaluation, and future research directions. IEEE Communications Magazine, 56(5), pp.46-52.
Ahmadi, M. and Aslani, N., 2018. Capabilities and advantages of cloud computing in the implementation of electronic health record. Acta Informatica Medica, 26(1), p.24.
Alam, T., 2021. Cloud Computing and its role in the Information Technology. IAIC Transactions on Sustainable Digital Innovation (ITSDI), 1, pp.108-115.
Alnumay, W.S., 2020. A brief study on Software as a Service in Cloud Computing Paradigm. Journal of Engineering and Applied Sciences, 7(1), pp.1-15.
Barik, R.K., Dubey, H., Misra, C., Borthakur, D., Constant, N., Sasane, S.A., Lenka, R.K., Mishra, B.S.P., Das, H. and Mankodiya, K., 2018. Fog assisted cloud computing in era of big data and internet-of-things: systems, architectures, and applications. In Cloud computing for optimization: foundations, applications, and challenges (pp. 367-394). Springer, Cham.
Buyya, R., Srirama, S.N., Casale, G., Calheiros, R., Simmhan, Y., Varghese, B., Gelenbe, E., Javadi, B., Vaquero, L.M., Netto, M.A. and Toosi, A.N., 2018. A manifesto for future generation cloud computing: Research directions for the next decade. ACM computing surveys (CSUR), 51(5), pp.1-38.
Chen, C., Chen, D., Yan, Y., Zhang, G., Zhou, Q. and Zhou, R., 2018. Integration of numerical model and cloud computing. Future generation computer systems, 79, pp.396-407.
El Kafhali, S., El Mir, I. and Hanini, M., 2021. Security Threats, Defense Mechanisms, Challenges, and Future Directions in Cloud Computing. Archives of Computational Methods in Engineering, pp.1-24.
Elhoseny, M., Abdelaziz, A., Salama, A.S., Riad, A.M., Muhammad, K. and Sangaiah, A.K., 2018. A hybrid model of internet of things and cloud computing to manage big data in health services applications. Future generation computer systems, 86, pp.1383-1394.
Garg, S., Singh, A., Kaur, K., Aujla, G.S., Batra, S., Kumar, N. and Obaidat, M.S., 2019. Edge computing-based security framework for big data analytics in VANETs. IEEE Network, 33(2), pp.72-81.
Habashi, F.S., Yousefi, S. and Jeddi, B.G., 2021. Resource allocation mechanisms for maximizing provider’s revenue in infrastructure as a service (iaas) cloud. Cluster Computing, pp.1-17.
Hosseinian-Far, A., Ramachandran, M. and Slack, C.L., 2018. Emerging trends in cloud computing, big data, fog computing, IoT and smart living. In Technology for smart futures (pp. 29-40). Springer, Cham.
Hu, Z., Gnatyuk, S., Koval, O., Gnatyuk, V. and Bondarovets, S., 2017. Anomaly detection system in secure cloud computing environment. International Journal of Computer Network and Information Security, 9(4), p.10.
Manogaran, G., Lopez, D., Thota, C., Abbas, K.M., Pyne, S. and Sundarasekar, R., 2017. Big data analytics in healthcare Internet of Things. In Innovative healthcare systems for the 21st century (pp. 263-284). Springer, Cham.
Manogaran, G., Lopez, D., Thota, C., Abbas, K.M., Pyne, S. and Sundarasekar, R., 2017. Big data analytics in healthcare Internet of Things. In Innovative healthcare systems for the 21st century (pp. 263-284). Springer, Cham.
Noor, T.H., Zeadally, S., Alfazi, A. and Sheng, Q.Z., 2018. Mobile cloud computing: Challenges and future research directions. Journal of Network and Computer Applications, 115, pp.70-85.
Odun-Ayo, I., Ananya, M., Agono, F. and Goddy-Worlu, R., 2018, July. Cloud computing architecture: A critical analysis. In 2018 18th international conference on computational science and applications (ICCSA) (pp. 1-7). IEEE.
Odun-Ayo, I., Ananya, M., Agono, F. and Goddy-Worlu, R., 2018, July. Cloud computing architecture: A critical analysis. In 2018 18th international conference on computational science and applications (ICCSA) (pp. 1-7). IEEE.
Psannis, K.E., Stergiou, C. and Gupta, B.B., 2018. Advanced media-based smart big data on intelligent cloud systems. IEEE Transactions on Sustainable Computing, 4(1), pp.77-87.
Sharma, P.K., Kaushik, P.S., Agarwal, P., Jain, P., Agarwal, S. and Dixit, K., 2017, October. Issues and challenges of data security in a cloud computing environment. In 2017 IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON) (pp. 560-566). IEEE.
Singh, A., Kumari, S., Malekpoor, H. and Mishra, N., 2018. Big data cloud computing framework for low carbon supplier selection in the beef supply chain. Journal of cleaner production, 202, pp.139-149.
Stergiou, C., Psannis, K.E., Gupta, B.B. and Ishibashi, Y., 2018. Security, privacy & efficiency of sustainable cloud computing for big data &IoT. Sustainable Computing: Informatics and Systems, 19, pp.174-184.
Stergiou, C., Psannis, K.E., Gupta, B.B. and Ishibashi, Y., 2018. Security, privacy & efficiency of sustainable cloud computing for big data & IoT. Sustainable Computing: Informatics and Systems, 19, pp.174-184.
Tang, B., Chen, Z., Hefferman, G., Pei, S., Wei, T., He, H. and Yang, Q., 2017. Incorporating intelligence in fog computing for big data analysis in smart cities. IEEE Transactions on Industrial informatics, 13(5), pp.2140-2150.
Yassine, A., Singh, S., Hossain, M.S. and Muhammad, G., 2019. IoT big data analytics for smart homes with fog and cloud computing. Future Generation Computer Systems, 91, pp.563-573.
Zanoon, N., Al-Haj, A. and Khwaldeh, S.M., 2017. Cloud computing and big data is there a relation between the two: a study. International Journal of Applied Engineering Research, 12(17), pp.6970-6982.
Zhang, R., 2018. The impacts of cloud computing architecture on cloud service performance. Journal of Computer Information Systems.
Zhang, W., Zhang, Z. and Chao, H.C., 2017. Cooperative fog computing for dealing with big data in the internet of vehicles: Architecture and hierarchical resource management. IEEE Communications Magazine, 55(12), pp.60-67.
Stergiou, C.L., Plageras, A.P., Psannis, K.E. and Gupta, B.B., 2020. Secure machine learning scenario from big data in cloud computing via internet of things network. In Handbook of computer networks and cyber security (pp. 525-554). Springer, Cham.
Singh, A., Kumari, S., Malekpoor, H. and Mishra, N., 2018. Big data cloud computing framework for low carbon supplier selection in the beef supply chain. Journal of cleaner production, 202, pp.139-149.